
티스토리 뷰
Analysis of Classifier-Free Guidance Weight Schedulers
https://arxiv.org/abs/2404.13040
Analysis of Classifier-Free Guidance Weight Schedulers
Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout th
arxiv.org
요약: CFG를 전체 타임스텝에 걸쳐서 일정하게 주는 것보다, 처음에 스케일 0에서 시작해서 점점 강하게 주는 것이 좋다 (linear, cosine). SD 1.5와 SDXL 모두에서 constant weight schedule보다 효과가 더 좋다. powered-cosine이나 clamped linear (ReLU 모양) 스케줄처럼 파라미터가 있는 스케줄러는 linear, cosine보다 더 잘되는 파라미터가 있지만 모델마다 최적의 파라미터가 다르다.
한계 (개인적 의견): '왜 잘 되는지'에 대한 설명이 부족하다. 잘 되는 이유는 concurrent work인 Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models (https://arxiv.org/abs/2404.0772) 에서 좀 더 보여주는 듯 (1d toy example로 보여줌)
머리속에 생각만 했던 1일 1논문 리뷰하기 시작!
최근에 좀 놀았더니 읽어야 할 논문이 산더미같이 쌓였다.
일단 최근 연구했던 가이던스 관련 논문들이 3월, 4월에 쏟아져나와서 그걸 위주로 리뷰하려고 한다.
효율성을 위해서 ChatGPT와 같은 LLM을 적극적으로 활용해서 리뷰하려고 한다.
영어 논문 읽는 실력도 늘려야 하긴 하지만.. 영어논문 읽기와 논문 많이 읽어서 최근 progress 빠르게 따라잡기를 동시에 하기는 힘들 것이라고 판단해서 일단 현대 문명의 이기에 의존해야겠다.

Abstract
분류기 없는 안내(CFG)는 텍스트-이미지 확산 모델의 품질과 조건 준수를 향상시킵니다. 고정 가중치를 사용하여 조건부 예측과 무조건 예측을 결합하는 방식으로 작동합니다(그림 1). 그러나 최근의 연구들은 확산 과정 전반에 걸쳐 가중치를 변화시키며 우수한 결과를 보고하지만 그 근거나 분석은 제공하지 않습니다. 이 페이퍼는 포괄적인 실험을 수행함으로써 CFG 가중치 스케줄러에 대한 인사이트를 제공합니다. 연구 결과에 따르면 단순하고 단조롭게 가중치 스케줄러를 늘리면 단 한 줄의 코드만 추가해도 지속적으로 성능이 향상되는 것으로 나타났습니다. 또한 더 복잡한 매개변수화된 스케줄러를 최적화하여 성능을 더욱 개선할 수 있지만, 다양한 모델과 작업에 일반화할 수는 없습니다.
1. Introduction
확산 모델은 이미지[1], 동영상[2], 음향 신호[3], 3D 아바타[4] 등 다양한 영역에서 뛰어난 생성 능력을 입증해 왔습니다. 확산을 통한 조건부 생성(예: 텍스트 조건부 이미지 생성)은 수많은 연구[5-7]에서 탐구되어 왔으며, 모델에 조건 입력을 추가하는 가장 간단한 형태로 이루어집니다[8]. 생성 과정에 대한 조건의 영향력을 높이기 위해 분류자 유도[9]는 개별적으로 훈련된 이미지 분류기의 기울기를 디퓨전 모델의 기울기와 선형적으로 결합할 것을 제안합니다. 또는 분류기 없는 안내(CFG)[10]는 조건부 모델과 무조건 모델을 동시에 훈련하고 베이지안 암시적 분류기를 활용하여 외부 분류기 없이도 조건 의존성을 달성할 수 있습니다. 두 경우 모두 가중치 파라미터 ω는 생성 및 안내 용어의 중요성을 제어하며 모든 시간 단계에서 직접 적용됩니다. 조건 의존도가 증가하면 충실도와 다양성이 모두 감소하는 경우가 많으므로 ω를 변경하는 것은 충실도와 조건 의존도 사이의 절충안입니다. 최근 일부 문헌에서는 정적 가이던스 대신 동적 가이던스라는 개념이 언급되기도 했습니다: MUSE [11]는 선형적으로 증가하는 안내 가중치가 성능을 향상시키고 잠재적으로 다양성을 증가시킬 수 있음을 관찰했습니다. 이 접근 방식은 Stable Video Diffusion [12]과 같은 후속 연구에서 채택되었으며, [13]에서는 특정 모델과 작업 쌍에서 매우 잘 작동하는 파라미터화된 코사인 기반 곡선(pcs4)에 대한 철저한 검색을 통해 추가로 언급되었습니다. 안타깝게도 이 주제가 최근 문헌에 등장했음에도 불구하고 참고된 연구 중 가이드 가중치 스케줄러의 사용을 입증하기 위한 실증적 실험이나 분석을 수행한 사례는 없습니다. 예를 들어, 선형 안내의 개념은 MUSE [11]에서 식 1을 중심으로 간략하게 언급되어 있습니다: “안내 스케일 t [...]를 선형적으로 증가시켜 다양성에 대한 영향을 줄임으로써 초기 토큰을 더 자유롭게 샘플링할 수 있도록 한다”. 마찬가지로, PC4 접근법[13]은 부록에서 간략하게만 설명되어 있으며, 정적 안내 기준선에 대한 자세한 설명이나 비교는 없습니다. 따라서 저희가 아는 한, 동적 안내 가중치 스케줄러에 대한 포괄적인 가이드는 현재 존재하지 않습니다. 이 백서에서는 확산 가이드의 동작을 자세히 살펴보고 생성에 미치는 영향을 체계적으로 조사하여 동적 스케줄러의 메커니즘과 개선의 근거를 논의함으로써 이러한 격차를 해소합니다. 다양한 휴리스틱 동적 스케줄러를 살펴보고 충실도, 다양성, 텍스트 준수에 초점을 맞춰 여러 작업에 걸쳐 휴리스틱 및 매개변수화된 동적 스케줄러의 종합적인 벤치마크를 제시합니다. 이러한 분석은 정량적, 정성적 결과와 사용자 연구를 통해 뒷받침됩니다. 그 결과는 다음과 같습니다:
첫째, 노이즈 제거 프로세스 초기에 너무 많은 안내를 제공하는 것은 해롭고 안내 스케줄러를 단조롭게 늘리는 것이 가장 성능이 좋다는 것을 보여주었습니다.
둘째, 선형적으로 증가하는 단순한 스케줄러가 기본 정적 안내보다 항상 결과를 개선하는 동시에 추가 계산 비용이 들지 않고 추가 튜닝이 필요하지 않으며 구현이 매우 간단하다는 것을 보여줍니다.
셋째, 선형 스케줄러를 신중하게 선택한 임계값(그림 1) 아래로 제한하는 것과 같이 매개변수화된 스케줄러는 결과를 훨씬 더 개선할 수 있지만 최적의 매개변수 선택이 모델과 작업 전반에 일반화되지 않으므로 대상 모델과 작업에 맞게 신중하게 튜닝해야 합니다. 이번 연구 결과는 CFG 스케줄러에 대한 가이드로서 CFG에 의존하는 모든 작업에 도움이 되고 개선될 것입니다.
2. Related Work
Generative and Diffusion Models.
확산 모델이 등장하기 전에는 주어진 데이터 세트를 무조건적으로 또는 조건부 지침을 통해 모방하는 새로운 데이터를 생성하기 위해 여러 가지 생성 모델이 개발되었습니다. 주목할 만한 성과로는 다양한 생성 작업에서 상당한 진전을 보인 변형 자동 인코더(VAE)[14]와 생성적 적대적 네트워크(GAN)[15]가 있습니다[16-19]. 최근 확산 모델은 고품질의 다양한 샘플을 생성할 수 있는 놀라운 능력을 보여주었습니다. 특히 이미지 합성[1, 20], 텍스트-이미지 애플리케이션[9, 21-23], 텍스트-모션[4] 등 여러 생성 작업에서 최첨단 결과를 달성했습니다.
디퓨전과 and Text-to-Image에서의 Guidance.
생성 모델을 제어할 수 있고 사용자에 맞춘 출력을 생성하려면 주어진 입력에 따라 조건부 생성 모델을 만들어야 합니다. 조건부 확산 모델은 광범위하게 연구되어 왔습니다[5-7]. 이 조건은 일반적으로 residual connection을 통해 외부 입력을 추가함으로써 가장 간단한 형태로 달성됩니다[8]. 특정 조건에 대한 모델의 충실도를 강화하기 위해 두 가지 주요 접근 방식이 널리 사용됩니다: 이미지 분류기를 외부에서 훈련하는 Classifier Guidance(CG)[9]와 조건부 및 무조건 모델의 공동 훈련(조건에 대한 드롭아웃 사용)을 통해 암시적 분류기에 의존하는 Classifier-Free Guidance(CFG)[10]가 그것입니다. 특히, CFG는 노이즈가 많은 텍스트 분류기를 훈련하는 것이 덜 편리하고 형태별 정확도가 떨어지는 영역인 text-conditioned generation의 발전을 촉진했습니다. 이 접근 방식은 처음에 [24, 25]와 같은 여러 연구에서 제안된 텍스트-이미지 애플리케이션에 새로운 생명을 불어넣었습니다. 수많은 연구[21, 26-28]에서 CLIP [29]과 같은 텍스트 인코더에 조건부 CFG 확산 모델을 사용한 텍스트-이미지 생성을 활용하여 이 분야에서 상당한 진전을 보였으며, Latent Diffusion Model[9] 및 Stable Diffusion[21]은 CLIP 인코더를 사용한 CFG에 VAE 잠재 공간 확산을 사용했습니다. 향상된 버전인 SDXL은 더 큰 모델과 고해상도 합성을 위한 추가 텍스트 인코더를 활용합니다.
Diffusion Guidance에서의 개선.
Classifier Guidance(CG)에서는 과신으로 인해 분류기의 그래디언트가 초기 및 최종 단계로 갈수록 사라지는 경향이 있습니다. 이러한 효과에 대응하기 위해 Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
(https://arxiv.org/pdf/2206.11474)[30]은 출력 분포의 엔트로피를 사라지는 기울기를 나타내는 지표로 활용하고 그에 따라 기울기를 재조정합니다. 이러한 adversarial한 행동을 방지하기 위해 Rethinking Conditional Diffusion Sampling with Progressive Guidance(https://openreview.net/pdf?id=gThGBHhqcU)[31]에서는 경험적 스케줄러를 사용하여 원하는 클래스에 집중하기 전에 노이즈 상태에서 이미지 클래스의 평균으로 이미지 생성을 유도하는 다중 클래스 조건을 사용하여 탐색했습니다. 그 후 PixelAsParam: A Gradient View on Diffusion Sampling with Guidance(https://openreview.net/forum?id=2q1Whv1kXL)[32]에서는 가이드에서 발생하는 그래디언트 충돌을 식별하고 정량화하여 그래디언트 projection을 해결책으로 제안했습니다.
CFG에서, Your diffusion model is secretly a zero-shot classifier(https://arxiv.org/abs/2303.16203)[33]은 여러 timestep에 걸쳐 샘플링하고 여러 라벨에 대한 가이던스 크기를 평균화하여 가장 낮은 크기가 가장 가능성이 높은 라벨에 해당하는 제로 샷 분류기를 복구하기 위해 CFG를 사용했습니다. 그러나 초기 단계가 중간 단계보다 정확도가 낮게 나오는 등 시간 단계에 따라 성능에 차이가 있음을 관찰했습니다.
Muse: Text-to-image generation via masked generative transformers(https://arxiv.org/abs/2301.00704)[11]에서는 가이던스 스케일이 선형적으로 증가하면 다양성이 향상되는 것을 관찰했습니다. 마찬가지로 Masked diffusion transformer is a strong image synthesize(https://arxiv.org/abs/2303.14389)[13]은 데이터 세트와 방법에 맞게 특정 파라미터를 최적화하는 파라미터화된 파워 코사인형 곡선을 개발했습니다. 그러나 이러한 선형 및 파워 코사인 스케줄러는 엄격한 분석이나 테스트 없이 일정한 정적 안내에 대한 개선점으로 제안되어 왔습니다. 이를 위해 여러 작업에 걸쳐 휴리스틱 스케줄러와 매개변수화된 스케줄러 모두에 대한 동적 안내에 대한 광범위한 연구를 제공합니다.
3. Background on Guidance
CG, CFG를 읽으면 다 알 내용이라고 생각한다.
혹시 리뷰가 필요하다면 다음 글을 참조하자.
https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/cfdg/
[논문리뷰] Classifier-Free Diffusion Guidance
Classifier-Free Diffusion Guidance 논문 리뷰 (NeurIPS Workshop 2021)
kimjy99.github.io
4. Dynamic Guidance: Heuristic Schedulers
최근 연구에서는 [9, 10]에서와 같이 CFG에 정적 가중치 ω를 사용하는 대신 노이즈 제거 확산 과정에서 진화하는 동적 가중치 가이드를 제안했습니다 [11, 12, 19]. 이 경우 CFG 방정식 3은 다음과 같이 재작성됩니다:
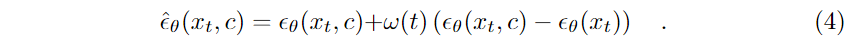
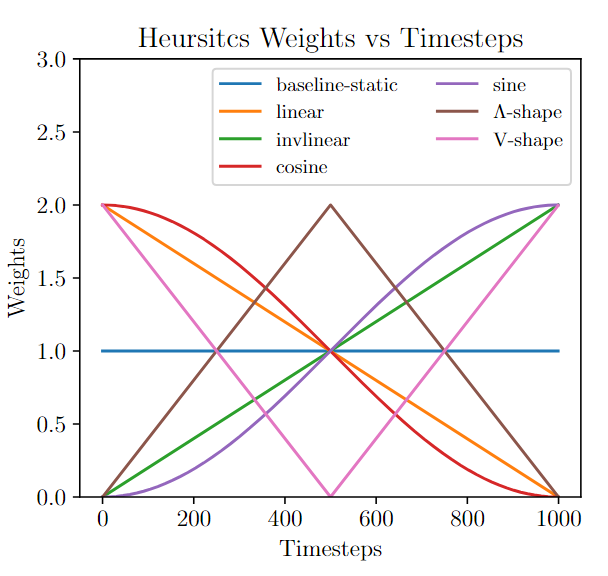
이를 밝히기 위해 다이나믹 가이던스 ω(t)로서 6가지 간단한 휴리스틱 스케줄러를 곡선의 모양에 따라 (a) 증가 함수(선형, 코사인), (b) 감소 함수(역선형, 사인), (c) 비단조 함수(선형 V형, 선형 Λ형)의 세 그룹으로 나누어 다음과 같이 정의합니다:
이러한 스케줄러의 효과와 정적 가이던스 ω를 직접 비교할 수 있도록 각 스케줄러를 곡선 아래 영역으로 정규화합니다. 이렇게 하면 전체 노이즈 제거 프로세스에 걸쳐 동일한 양의 총 가이던스가 적용되고 사용자가 스케줄러의 크기를 조정하여 정적 가이던스에서 ω를 증가시키는 것과 유사한 동작을 얻을 수 있습니다.
보다 공식적으로 이것은 다음 제약 조건에 해당합니다:
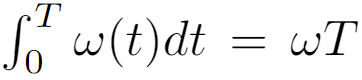
4.1 Class-conditional image generation with heuristic schedulers
휴리스틱 스케줄러 분석.
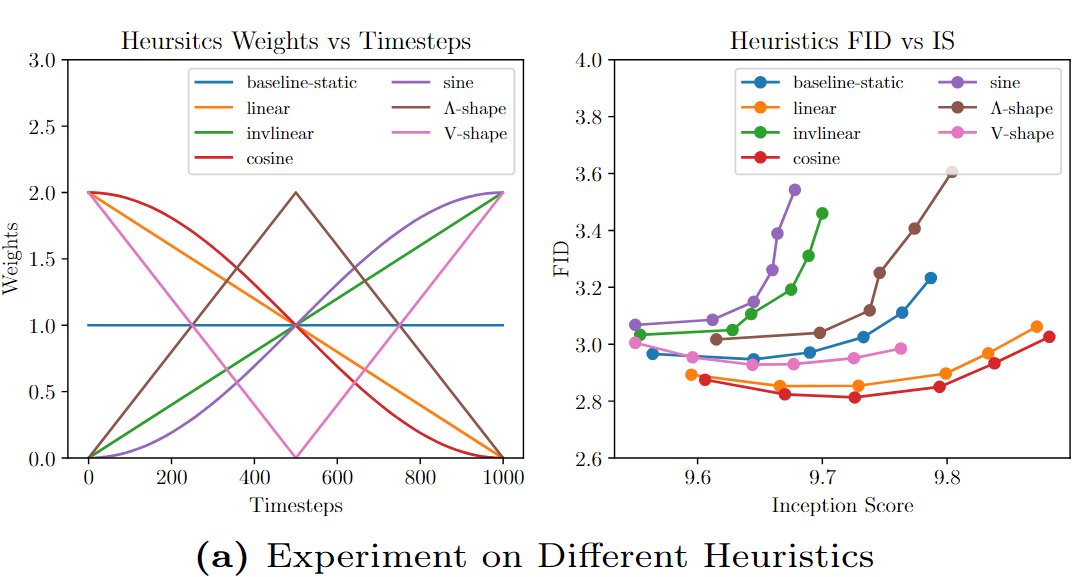
먼저 10개의 클래스에 분산된 해상도 32×32픽셀의 60,000개 이미지 데이터 세트인 CIFAR-10 데이터 세트에 대해 이전에 정의된 6개의 휴리스틱 스케줄러 ω(t)를 연구합니다. 첫 번째 분석은 픽셀 공간에서 노이즈를 제거하는 원래의 DDPM 방법[1]과 클래스 조건부 합성을 위한 CFG[10]에 의존합니다. 성능을 평가하기 위해 50단계 DDIM [20]을 통해 수행된 50, 000회 이상의 추론을 통해 얻은 Frechet Inception Distance(FID) 및 시작 점수(IS) 메트릭을 사용합니다. 이 실험에서는 [1.1, 1.15, 1.2, 1.25, 1.3, 1.35]의 다양한 가이드 총 가중치의 영향을 평가하여 이미지 품질 대 클래스 준수 트레이드오프에 대한 영향을 연구합니다. 그 결과는 그림 5a의 가운데 패널에 나와 있습니다. 증가하는 스케줄러(선형 및 코사인. t = 1000에서 시작하므로 그래프 개형의 오른쪽부터 보기)는 모두 정적 기준선보다 크게 개선되는 반면, 감소하는 스케줄러(인비선형 및 사인)는 정적보다 유의미하게 나빠지는 것을 관찰할 수 있습니다. V자형 및 Λ자형 스케줄러는 정적 기준선보다 각각 더 나은 성능과 더 나쁜 성능을 보이지만 미미한 차이에 불과합니다.
Negative Perturbation 분석.
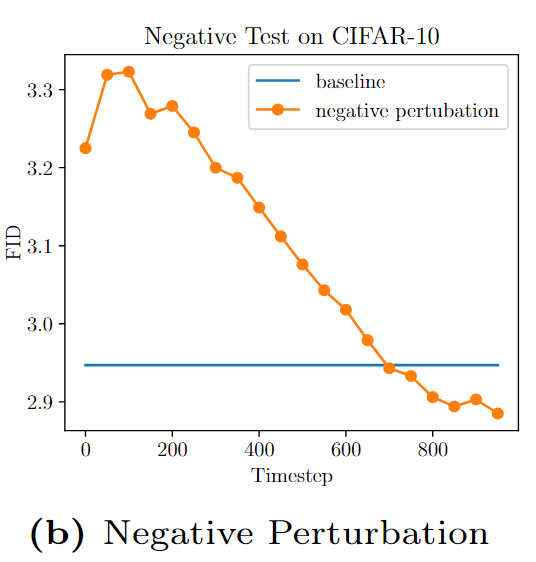
여기서는 위와 동일한 CIFAR-10-DDPM 설정을 사용하여 다양한 시간 간격에서 안내의 중요도를 조사합니다. 스케일 ω = 1.15의 정적 안내를 사용하고 50개 타임스텝(전체 타임스텝에 걸쳐 총 20개 간격)의 서로 다른 간격 내에서 독립적으로 가이던스를 0으로 설정합니다. 결과물인 각 조각별 제로화 스케줄러에 대한 FID를 계산하고 그 결과를 그림 5b에 표시합니다. 노이즈 제거의 초기 단계에서 가이드를 제로화하면 FID가 개선되는 반면, 이후 단계에서 가이드를 제로화하면 FID가 크게 저하되는 것을 관찰할 수 있습니다. 이 관찰은 단조롭게 증가하는 스케줄러가 가장 좋은 성능을 보인 이전 섹션의 결과와 일치하며, 스케줄러를 증가시키는 선택에 힘을 실어줍니다.
예비 결론.
앞선 두 분석은 모두 단조롭게 증가하는 가이던스 스케줄러가 더 나은 성능을 달성한다는 동일한 결론을 가리키며, 정적 CFG의 한계는 주로 프로세스 초기 단계에서 가이던스를 과도하게 촬영하는 데서 비롯된다는 점을 드러냅니다. 이 작업의 나머지 부분에서는 다른 작업에서 다른 모든 스케줄러를 검토하지 않기에 이러한 결과를 충분히 고려하기 위해 단조롭게 증가하는 스케줄러만 고려합니다.
ImageNet에서의 실험.
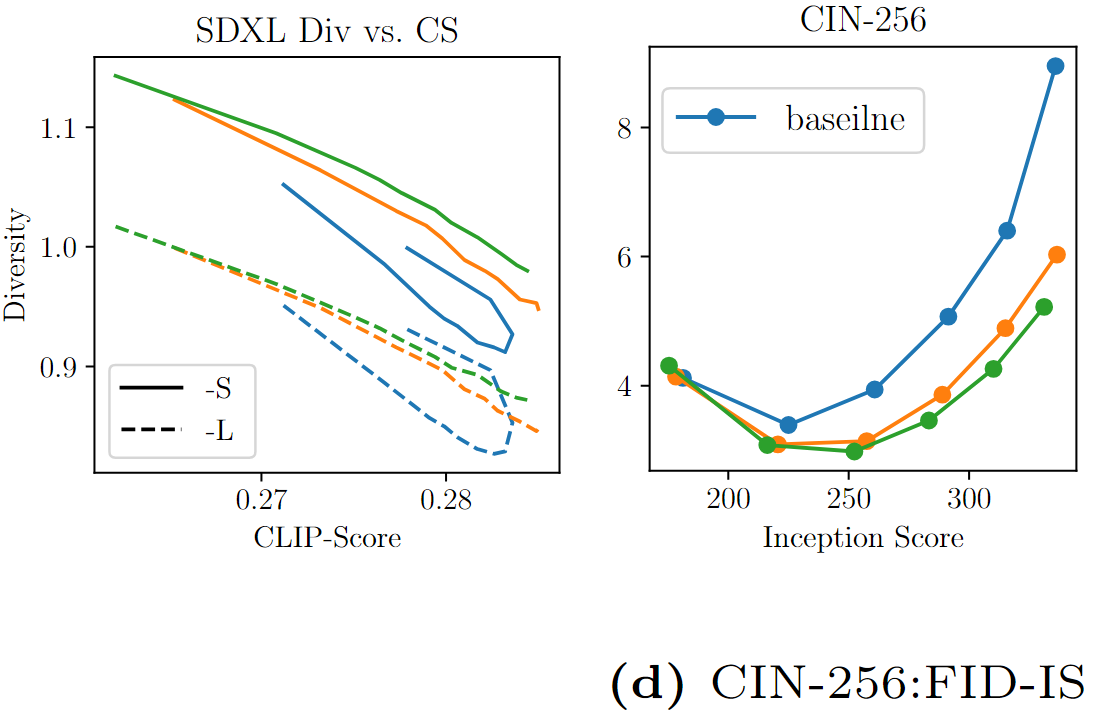
ImageNet에서 CIFAR-10에서 가장 우수한 성능을 보인 선형 스케줄러와 코사인 스케줄러를 살펴봅니다. 그림 6d에서 선형 및 코사인 스케줄러는 특히 높은 안내 가중치에서 기준선보다 크게 개선되어 더 나은 FID/초기 점수 절충을 가능하게 하는 것을 관찰할 수 있습니다. supplementary materials에서 더 많은 실험을 수행해도 비슷한 결론을 얻을 수 있습니다.
4.2 Text-to-image generation with heuristic schedulers
텍스트-이미지 생성에 대한 선형 및 코사인 스케줄러를 연구합니다. 제안된 모든 휴리스틱에 대한 결과는 supplementary materials에 나와 있습니다. 표 11과 13에서 이전과 비슷한 추세를 관찰할 수 있습니다. 모양이 증가하는 휴리스틱 함수는 SD1.5와 SDXL 모두에서 가장 큰 이득을 보고합니다.
데이터 세트 및 메트릭.
우리는 LAION[34]에서 사전 학습된 텍스트-이미지 모델을 사용하며, 여기에는 50억 개의 고품질 이미지와 쌍을 이루는 텍스트 설명이 포함되어 있습니다. 평가를 위해 30, 000개의 텍스트-이미지 페어링 데이터로 구성된 COCO [35] 값을 사용합니다. (i) 생성된 이미지의 충실도를 위한 프레셰 시작 거리(FID), (ii) 이미지와 해당 텍스트 프롬프트 간의 정렬을 평가하기 위한 클립 점수(CS)[29], (iii) 다양한 콘텐츠를 생성하는 모델의 역량을 측정하기 위한 다양성(Div) 등 세 가지 지표를 사용합니다. 이를 위해 동일한 프롬프트의 여러 세대에 걸친 Dino-v2[36]를 통해 이미지 임베딩의 표준 편차를 계산합니다(다양성에 대한 자세한 내용은 서플에서 확인하세요.). 10, 000개의 이미지 샘플 세트에 대해 제로 샷 방식으로 COCO dataset에 대해 FID와 CS를 계산합니다[5,21]. 다양성을 위해 COCO의 두 가지 텍스트 설명 하위 집합, 즉 가장 긴 캡션과 가장 짧은 캡션 각각 1000개(그림 6a의 -L 및 -S)를 사용하여 다양한 설명 수준을 나타냈는데, 긴 캡션은 짧은 캡션보다 더 구체적인 조건을 제공하므로 다양성이 떨어질 것으로 예상됩니다. 다양한 샘플링 노이즈를 사용하여 각 프롬프트에 대해 10개의 이미지를 생성합니다.
모델.
(1) CLIP [29] 텍스트 인코더를 사용하여 텍스트 입력을 임베딩으로 변환하는 안정적 확산(SD) [21]의 두 가지 모델을 실험합니다. SD v1.5 1의 공개 체크포인트를 사용하며 50단계의 DDIM 샘플러를 사용합니다. (2) SDXL[22]은 SD[21]의 더 큰 고급 버전으로 최대 1024픽셀의 해상도로 이미지를 생성합니다. 더 큰 U- Net 아키텍처, 추가 텍스트 인코더(OpenCLIP ViT-bigG) 및 기타 향상된 컨디셔닝 기능을 갖춘 LDM [9]을 활용합니다. 리파이너 없이 SDXL-base-1.02(SDXL) 버전을 사용하며, 25단계의 DPM-Solver++[37]로 샘플링합니다.
결과.
SD의 경우 그림 6a, SDXL의 경우 그림 6c에 FID 대 CS 곡선이 표시되어 있습니다(자세한 표는 위 표 참조). 높은 CS와 낮은 FID 사이의 최적의 균형이 예상됩니다(그래프의 오른쪽 아래 모서리).
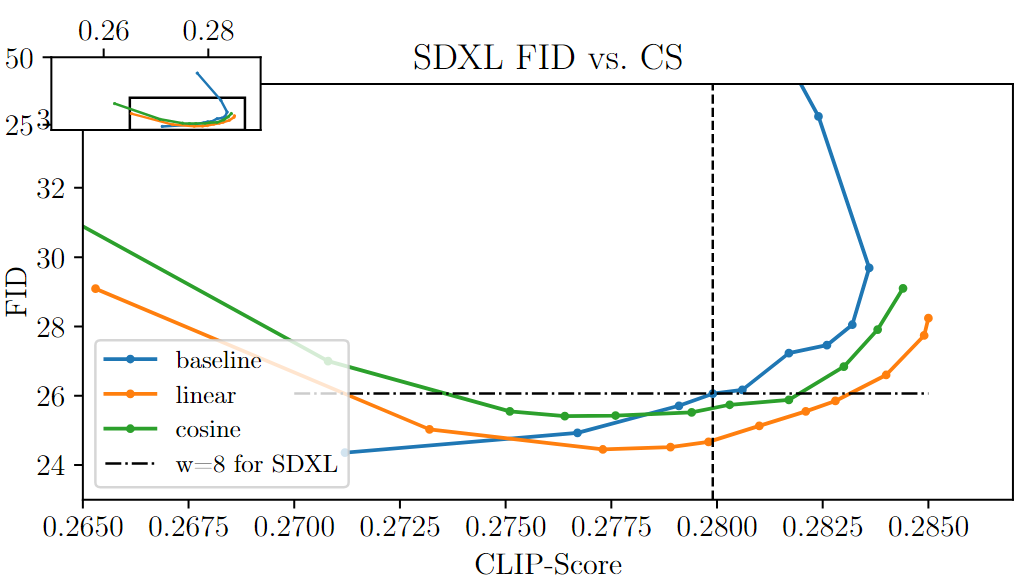
SD에 대한 분석(그림 6a).
FID 대 CS의 경우, 기준선[21]은 선형 및 코사인 휴리스틱에 비해 선형 기록이 낮은 FID로 인해 열등한 결과를 산출합니다. 베이스라인은 CS가 높을 때 FID를 빠르게 회귀시키지만, CS가 낮을 때 즉, 조건 수준이 낮을 때 가장 좋은 FID를 생성합니다. 그러나 이는 일반적으로 실제 애플리케이션에는 사용되지 않습니다. 예를 들어 SD1.5의 경우 권장되는 ω 값은 7.5이며, 그림 6a의 점선으로 강조 표시된 검은색 실선 화살표는 각각 FID와 CS에서 휴리스틱 스케줄러의 이득을 나타냅니다. Div와 CS의 경우, 휴리스틱 스케줄러는 다양한 안내 척도에서 짧은 캡션(S)과 긴 캡션(L) 모두에서 기준선[21]보다 우수한 성능을 보였습니다. 또한 코사인은 대부분의 클립 점수 범위에서 우위를 보였습니다. 전반적으로 휴리스틱 스케줄러는 FID 및 다양성에서 향상된 성능을 달성하여 SD에서 ω=7.5 기본 가이던스 이상의 CS에서 2.71(17%) 이득과 0.004(16%) 이득(기준선의 최대 CS-min CS)을 기록했습니다. 이 이득은 하이퍼파라미터 튜닝이나 재훈련 없이도 달성할 수 있습니다. SDXL에 대한 분석(그림 6c). FID에서는 선형 스케줄러와 코사인 스케줄러 모두 기준선보다 더 나은 FID-CS를 달성합니다[22]. 다양성에서는 선형이 코사인보다 약간 낮지만, 둘 다 정적 기준선보다 우수합니다. 또한 일반적으로 지침이 높을수록 FID가 저하되는 기준선(파란색 곡선)과 달리 휴리스틱 스케줄러는 이에 대응합니다.
User Study.
사용자에게 9개의 이미지로 구성된 모자이크 한 쌍을 제시하고 사실성, 다양성, 텍스트-이미지 정렬 측면에서 가장 좋은 이미지에 투표하도록 요청합니다. 각 쌍은 정적 기준선 생성과 코사인 및 선형 스케줄러를 비교합니다. 그림 6b는 그 결과를 보여줍니다. 60% 이상의 사용자가 스케줄러가 생성한 이미지가 더 사실적이고 텍스트 프롬프트와 더 잘 일치한다고 생각하는 반면, 약 80%는 안내 스케줄러의 결과가 더 다양하다고 생각하는 것으로 나타났습니다. 이는 정적 가중치가 동적 가중치보다 지각적으로 열등하다는 가설을 뒷받침하는 결과입니다. 자세한 내용은 위에서 확인하세요.
정성적 결과.


그림 3은 SD와 SDXL의 다양한 텍스트-이미지 생성 세트의 충실도를 보여줍니다. 휴리스틱 스케줄러(선형 및 코사인)가 꽃 이미지의 꽃잎과 잎의 디테일과 새 특징의 질감을 개선하는 등 이미지의 충실도를 향상시키는 것을 관찰할 수 있습니다. 아치 예시에서는 보다 자연스러운 색상 음영과 반사 효과가 있는 더 세밀한 형상을 관찰할 수 있습니다. 그림 4는 구도, 색상 팔레트, 아트 스타일 및 이미지 품질 측면에서 음영을 다듬고 텍스트를 풍부하게 함으로써 다양한 결과물을 보여줍니다. 특히 곰 인형은 비슷한 구도로 축소된 기준선보다 다양한 구도와 더 나은 색상의 결과물을 보여줍니다. 마찬가지로 우주비행사 예시에서 기준선은 비슷한 이미지를 생성하는 반면 휴리스틱 스케줄러는 더 다양한 캐릭터 제스처, 조명 및 구도에 도달합니다.
4.3 Findings with heuristic schedulers
요약하면, 단조롭게 증가하는 휴리스틱 스케줄러(예: 선형 및 코사인)는 (a) static baseline보다 생성 성능이 향상되고, (b) 감소하는 가이던스 스케줄러보다 성능이 향상되며, (b) 이미지 충실도(질감, 디테일), 다양성(구도, 색상, 스타일) 및 이미지 품질(조명, 제스처)이 향상된다는 사실을 확인할 수 있습니다. 이러한 이점은 하이퍼파라미터 튜닝, 모델 재교육 또는 추가 계산 비용 없이도 달성할 수 있다는 점에 주목할 필요가 있습니다.
5. Dynamic Guidance: Parametrized Schedulers
파라미터가 있는 스케줄러 (power cosine curve (아래 그림 참조), clamped linear function)을 파라미터 바꿔가면서 테스트함
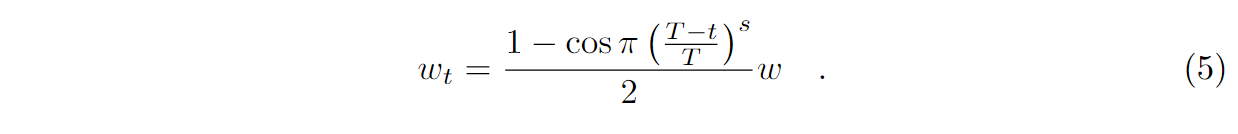
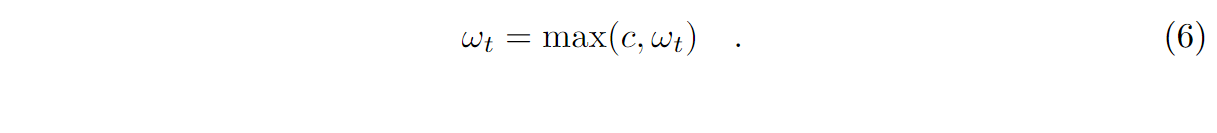
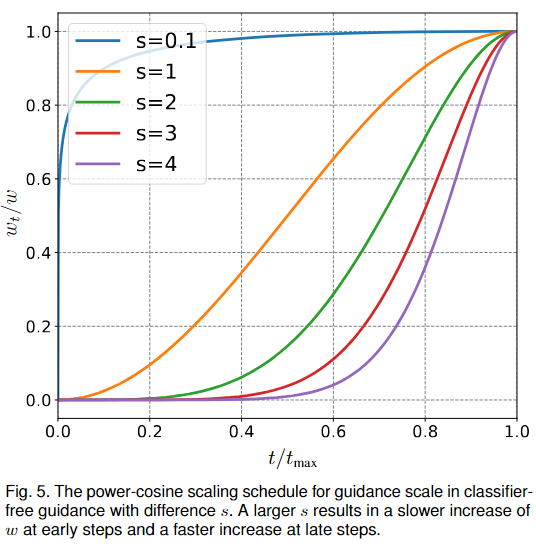
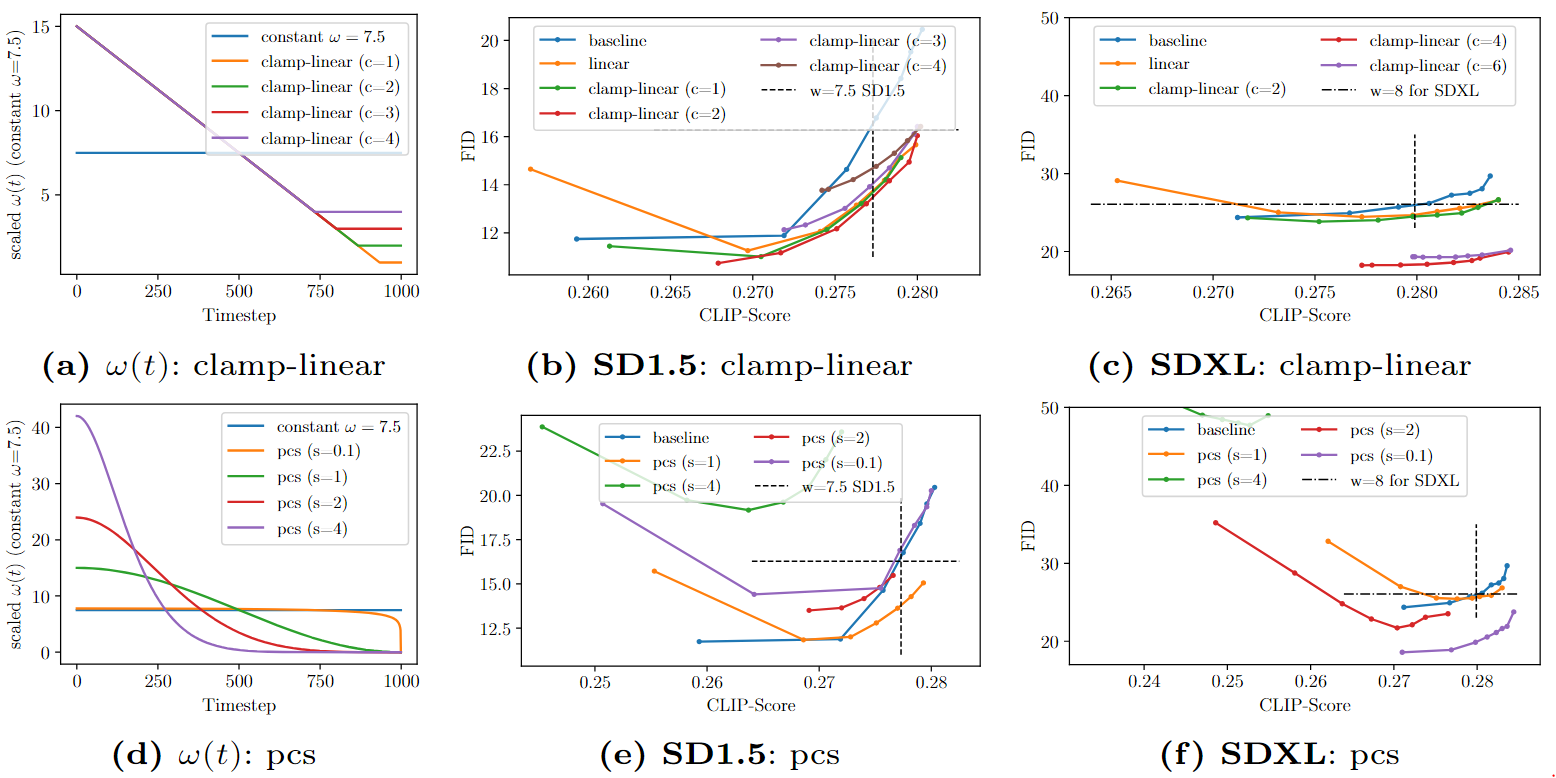
파라미터가 없는 스케줄러보다 성능이 개선되는 스케줄러들이 있으나, 모델에 따라 optimal 파라미터가 다르다.
6. Conclusion
우리는 경험적 스케줄러와 매개변수화된 스케줄러를 체계적으로 비교하여 Classifier-Free Guidance에서 가중치 매개변수에 대한 동적 스케줄러를 분석했습니다. 우리는 두 가지 작업(클래스 조건 생성 및 텍스트-이미지 생성), 여러 모델(DDPM, SD1.5 및 SDXL) 및 다양한 데이터 세트를 실험합니다. 논의. 우리의 연구 결과는 다음과 같습니다. (1) 간단한 단조롭게 증가하는 스케줄러는 추가 계산 비용이나 하이퍼 매개변수 검색 없이 일정한 정적 안내에 비해 성능을 체계적으로 향상시킵니다. (2) 작업, 모델 및 데이터세트별로 매개변수가 조정된 매개변수화된 스케줄러는 결과를 개선합니다. 그러나 모든 작업에 적합한 보편적인 매개변수가 없기 때문에 다른 모델 및 데이터 세트로 잘 일반화되지 않습니다. 최첨단 성능을 목표로 하는 실무자의 경우 최상의 클램핑 매개변수를 검색하거나 최적화하는 것이 좋습니다. 사례별로 매개변수를 수동으로 조정하고 싶지 않은 경우 휴리스틱, 특히 선형 또는 코사인을 사용하는 것이 좋습니다.
'인공지능 > 논문리뷰' 카테고리의 다른 글
| [논문리뷰] Fixed-point Inversion for Text-to-image diffusion models (0) | 2024.05.08 |
|---|